
值,或是參考
我們先來看看值型別吧
掏出瀏覽器,在console試試下面的程式
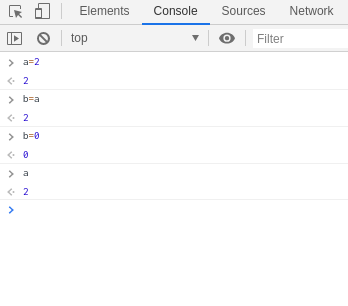
ㄜ... 有什麼問題嗎?
這部份當然沒問題,有問題的是
再試試下面的程式吧

好,這部份就有問題了
問題在於為什麼修改了b卻連a也一起變動了對吧
究竟發生了什麼事?
理由在於在js中物件屬於參考型別
與值型別最不一樣的地方在於值型別是將值丟入變數內

也因此如果你將值給予其他變數時,是將變數給他

但是參考型別則是賦予變數記憶體位置
const a = {v:10}
是js裡面宣告物件的方式
但是a裡面存的卻不是物件的值,而是物件的位置

也因此當你將a賦值給b時其實是將a所儲存的記憶體位置給b
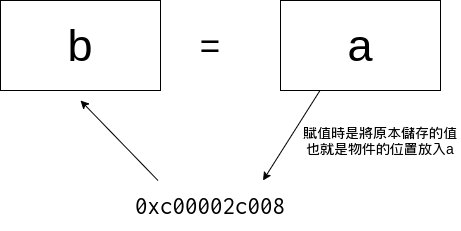
也因此實際上這時候a跟b都同時代表著剛才宣告出來的物件
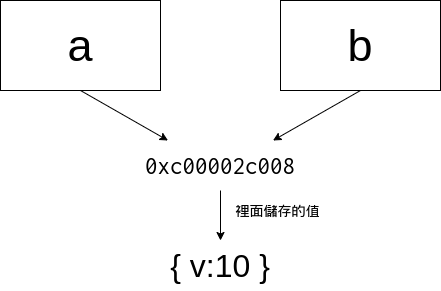
也因此當你修改了b或a時,實際上是修改那個記憶體位置內的物件
所以當你修改完後另外一個也會跟著改變
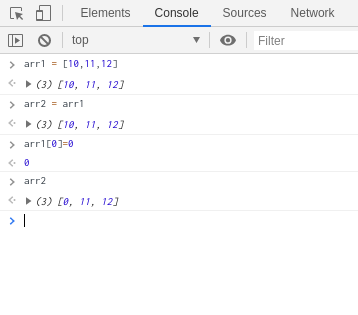
在js內,除了物件以外陣列其實也是參考型別喔
試試下面的程式碼吧
這點在golang也是類似的情況
package main
import (
"fmt"
)
func main() {
a := []int{10,11,12}
fmt.Println(a) // [10 11 12]
b := a
b[0] = 0
fmt.Println(a) // [0 11 12]
}
你可以在golang的遊樂場中嘗試上面的程式碼
這樣做有什麼好處嗎?
好處在於物件或陣列通常都比較難以安排記憶體的位置
比方說int你可以知道要幫他保留32bits(按照語言會有所不同)
而物件或陣列做不到
物件由於是基本型別組裝而成,因此裡面可能有string,int之類的.因此難以安排一整段的記憶體位置
陣列也是因為需要根據內部的資料來決定需要佔用多大的記憶體,
當你的陣列從3拓展到30時,雖然還是同一個變數,但是佔用的空間大小完全不同
因此你會在js看到這樣的操作
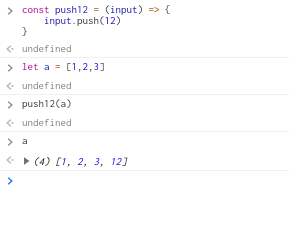
但是如果不是操作變數而是一般的int會有完全不同的結果
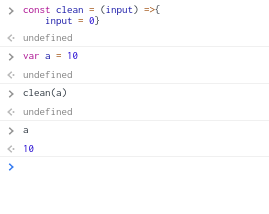
修改了方法的輸入值並不影響傳入的變數
同樣的道理在python也適用
def push(input):
input.append(12)
def clean(input):
input = 0
a = [1,2,3]
push(a)
print(a) # 1,2,3,12
b = 10
clean(b)
print(b) #10
你可以在線上版python玩
可以看到若是在方法內傳入陣列,那麼在方法內改變的值將會影響到原始的資料
但是如果是一般的int則不會
那如果我想要在方法內改變傳入的整數值呢?
這時候你就需要
開一個新的.cpp檔吧
#include <iostream>
using namespace std;
int main(){
int a = 10;
int b = a;
b= 2;
cout << "a: " << a << endl; //10
cout << "b: " << b << endl; //2
int &c = a;
c = 2;
cout << "a: " << a << endl; //2
cout << "b: " << b << endl; //2
}
如果直接宣告一個新的變數並將值賦給他
int b = a;
那就是單純的值複製,如同常見的用法
但是C++有參考宣告
int &c = a;
在變數前面加上&就可以將其宣告成參考
效果等同我們在前面所使用的陣列傳遞,差別在於由於陣列本身就是參考型別,因此不需要特地加上&
好,那麼C++究竟是怎麼做到的呢
理由在於賦予兩個變數相同的記憶體位置(也就是指向同一個目標)
在剛才的程式碼加上最下面這三行吧
cout << "&a: " << &a << endl;
cout << "&b: " << &b << endl;
cout << "&c: " << &c << endl;
最後應該會呈現這樣的結果
&a: 0x7ffc10b9dc18
&b: 0x7ffc10b9dc1c
&c: 0x7ffc10b9dc18
你顯示的值可能跟我的不太一樣,但是&a跟&c會是一樣
這是什麼?
這是變數儲存的記憶體位置,使用&將會為你取出他
不是說&表示宣告參考嗎? 怎麼變成取出記憶體位置?
兩者都是對的,因為在C++,記憶體位置跟參考都是使用&
這是很容易搞混的觀念,但是別搞混了
參考跟記憶體位置並不是等價的
那麼,取出記憶體位置的用途是什麼呢?
那就要談到C/C++最令人害怕的東西了
繼續往下增加你的程式碼吧
int *d = &a;
cout << "d: " << d << endl;
cout << "*d: " << *d << endl;
cout << "&d: " << &d << endl;
輸出應該會是
d: 0x7ffc8c6a60e8
*d: 2
&d: 0x7ffc8c6a60f0
int *d 是什麼?
這個稱之為指標
指標有許多種寫法
int *c
int* c
int*c
表達的意思完全相同
指標的是說我們在這個變數裡面存的並不是一個值,而是一個記憶體位置
而這個記憶體位置的資料,型別為int
結果如下
| 變數名稱 | 型別 | 資料內容 | 記憶體位置 |
|---|---|---|---|
| a | int | 2 | 0x7ffc8c6a60e8 |
| d | *int | 0x7ffc8c6a60e8 | 0x7ffc8c6a60f0 |
因此當我們印出d時,會直接印出裡面儲存的記憶體位置
而當我們印出*d時,會去撈出記憶體位置內的資料,這時我們才會拿到2
而當我們印出&d時,實際上是去取得d這個變數的記憶體位置
這也是為什麼印出d會跟印出&a得到相同的結果,因為&a就是取得記憶體位置,
而我們已經將其儲存於d這個int*型別的變數中了
ㄜ... 所以到底有什麼用?
修改你的程式碼或是開一個新的檔案吧
#include <iostream>
using namespace std;
void add(int input);
void add2(int *input);
int main(){
int a = 10;
add(a);
cout<< "add(a): " << a << endl; // 10
add2(&a);
cout<< "add2(&a): " << a << endl; // 11
}
void add(int input){
input = input+1;
}
void add2(int *input){
*input = *input+1;
}
你可以看到如果你帶入的一般的變數,那麼在方法內修改的值將不會影響到外面的變數
而若你是帶入記憶體位置,並且直接去修改記憶體位置內的值的話,就會影響到外面的變數
這樣的好處是就算不是參考型別,也可以正確的抓到資料的原始位置
這就是指標的好處之一
另外,當今天你在傳值時,如果你傳遞一個普通的變數,就會把整個變數內的東西複製過去
而若你傳遞的是一個變數的參考,就只會把記憶體位置給複製過去
在效能上及空間上都節省許多
這就是指標的好處之二
你可以在golang的遊樂場玩玩看下面的程式碼
package main
import (
"fmt"
"unsafe"
)
type compose struct {
check bool
order int
imfor string
}
func main() {
check := true
order := 100
imfor := "this is imformation in struct"
fmt.Println(unsafe.Sizeof(check)) // 1
fmt.Println(unsafe.Sizeof(order)) // 8
fmt.Println(unsafe.Sizeof(imfor)) // 16
com1 := compose{check,order,imfor}
checkSize(com1) // 32
com2 := &compose{check,order,imfor}
checkSizeStr(com2) // 8
}
func checkSize(input compose){
fmt.Println("size of com",unsafe.Sizeof(input))
}
func checkSizeStr(input *compose){
fmt.Println("size of com2",unsafe.Sizeof(input))
}
golang的struct你可以看作資料的集合體
雖然golang有提供讓struct模擬物件的寫法,但實際上struct並不是物件,因此並不是參考型別
因此當你查看struct的大小時就會是三個型別加起來的大小(1+8+16會等於32是因為記憶體排列的問題)
但是當你傳遞的是一個物件的指標時,大小就只有8(bytes)
指標就是可以讓你升效能與節省記憶體的工具
不過
前提示你必須非常了解指標到底在做什麼
試試下面的程式碼吧
package main
import (
"fmt"
)
func main() {
a := 5
add(&a)
fmt.Println(a) // 5
add2(&a)
fmt.Println(a) // 10
}
func add(input *int){
fmt.Println(input) // 0xc00002c008
temp := 10
input = &temp
}
func add2(input *int){
fmt.Println(input) //0xc00002c008
temp := 10
*input = temp
}
有看出add及add2的差異嗎?
明明都特地傳了記憶體位置進去了,但是第一種作法a的值並沒有改變
使用了指標,並不代表你就可以穩穩的使用操作記憶體了
實際上,指標只是讓你在變數內儲存記憶體位置,而不是直接對那個記憶體內的東西做改動
因此,如果你去看變數的記憶體位置
func add(input *int){
fmt.Println(input) // 0xc00002c008
fmt.Println(&input) // 0xc00000e028
temp := 10
input = &temp
}
func add2(input *int){
fmt.Println(input) // 0xc00002c008
fmt.Println(&input) // 0xc00000e038
temp := 10
*input = temp
}
會發現雖然input相同,但實際上兩個變數的記憶體位置是完全不同的
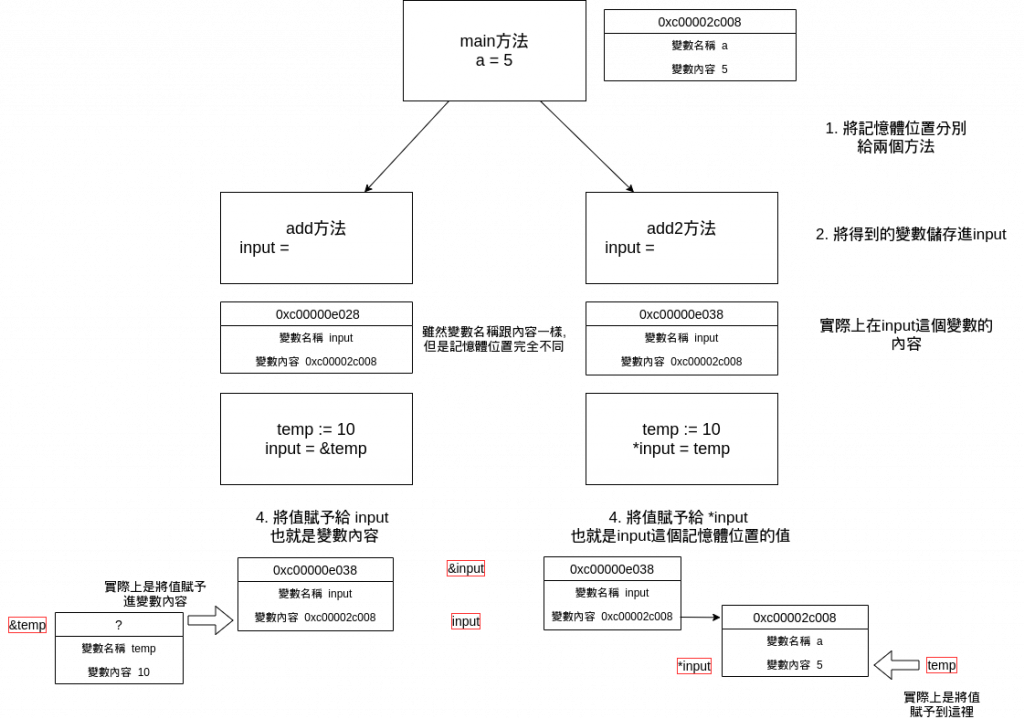
懂了嗎?
input = &temp
實際上是改動了input內的值(也就是方法內的變數的值)因此不會影響到方法外面的變數
而
*input = temp
則是改動了input這個記憶體位置內儲存的值
因此,當你在做指標的操作時,必須盡可能搞清楚指標的內容跟他們的含意
如果繼續深入研究,你會發現指標有很多有趣的玩法
**a //指標的指標
*&a
&*a
如果你選擇的語言沒有指標,那麼恭喜你,你可以不必深入理解他們的概念
但是至少需要理解參考,畢竟大部分的語言陣列跟物件都是參考型別
指標最容易讓人混搖的部份是因為指標的名稱與符號是被重複利用的
簡單劃分的話大概會是下面的情況
至於現在這個符號表達什麼則會根據當時使用的情況來決定
有些語言是沒有參考符號(&)的,因此看到&就當作取出記憶體位置吧
如果有任何寫不清楚或是觀念沒有很明白的話請留言告知我
會盡快補上
如果有任何寫錯的地方也麻煩留言告知我
會盡快修正
感謝各位
